

Frictionful Intelligence
The cost of compute rises, a three part thought experiment

revisiting Citrini’s exactly wrong doomcast
from tokenmaxxing to token-rationing, the juice must scale with the squeeze
of gpu rental rates and silicon data
what does “AI demand,” mean anyway? considering the outer limits, and what it might take to bend the curve upwards
software-but-better, or conquering new lands
👉👉👉Reminder to sign up for the Weekly Recap only, if daily emails is too much. Find me on twitter, for more fun. 👋👋👋Random Walk has been piloting some other initiatives and now would like to hear from broader universe of you:
(1) 🛎️ Schedule a time to chat with me. I want to know what would be valuable to you.
(2) 💡 Find out more about Random Walk Idea Dinners. High-Signal Serendipity.Reality Bites: Frictionful Intelligence
In what seems like ages ago, Citrini published a long report about how the cost of “frictionless” intelligence was going to collapse to zero, and then everything would go to hell in a handbasket.
At the time, Random Walk was polite, and said “Citrini Asks All the Wrong Questions,” but really the report was kinda dumb, especially on its core premise. The notion that compute was “frictionless,” is exactly wrong, and if anything, all the hard questions are around the impact of that friction.
Indeed, one of the biggest differences between AI and tech-splosions of yore, is that AI is not zero-marginal cost. Every push of the AI button costs money, such that selling AI-native software consumes gross margin.
Likewise, the real concern isn’t general stagnation once the cost of intelligence goes to zero, but rather that the exceedingly high cost of intelligence would grow more quickly than the quantifiable gains that would justify paying for it—or, perhaps more precisely, the incremental costs of model improvements are higher than the incremental gains of better models to enough customers.1
In that case, if LLM prices went up commensurate with costs, that could negatively impact demand (and create an “overhang” of expensive model development without an end-market).
Conversely, given competitive pressures to “race to the bottom” on price and maintain the leading model (and stave off open weight competition), frontier labs may have a hard time passing their development/compute costs on to customers, even if those customers could justify paying more.
Either way, customers (and/or investors) have to be willing to pay the labs, for the labs to pay the hyperscalers, for the hyperscalers to pay the chip- and datacenter-makers. If not, the music stops, or at least, slows.
The downside fear isn’t “dark fiber,” (where cables are laid, but unused, as per Dotcom), but under-priced fiber, that goes dark(er) once real costs (including energy) are passed-through.
Again, to analogize to cellphones, lots of people surely would have had uses for the first gen big clunky things, but not at prices that would have justified making big clunky things for a mass market. That’s why, in the beginning, only the stereotypical “rich a-hole from an 80’s movie” had one. Eventually, phones got less clunky, added a lot more utility, and became cheaper, and the mass market was, perhaps, bigger than people even imagined. But, all the while, investment scaled with market size to keep things relatively in check.
When investments run ahead of the actual realizable market, that’s what you might call a “bubble,” and obviously that’s concerning.
Things that are not concerning, on the other hand, are the possibilities that:
AI isn’t useful (call it the “hater scenario”)—if anything, lower costs seem to increase demand; and/or that
AI is so useful that nothing else is (i.e. the Citrini scenario).
So, why bring this up?
Well, in the first instance, recently there has been an emerging concern that token costs are, in fact, beginning to weigh on demand. Does it have legs? Let’s see.
ICYMI





Tokenmaxxing to token-rationing
Fairly recently, there was some anecdata of high profile companies (e.g. Uber, Meta, etc.) reversing their “token maxxing,” mantras, in favor of some more disciplined cost management.
Those companies do not appear to be alone:

In general, “token costs,” are becoming a point of interest in calls with analysts, management and experts, per AlphaSense.
Likewise, other soft data suggests that IT spending intentions, while still high, are cooling somewhat:
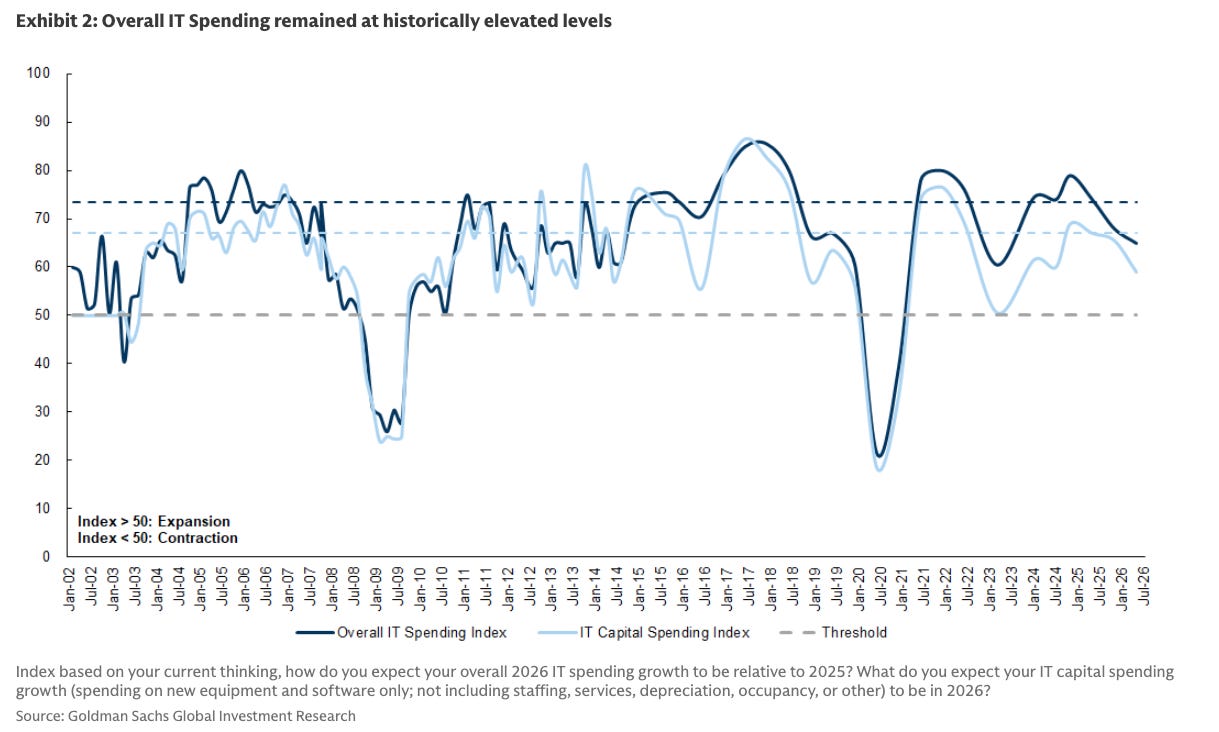
The majority of respondents still expect IT budgets to grow, but the level is coming closer to 60% (off the near record-highs from 2 years ago). Plus, estimates for the magnitude of growth have down-shifted somewhat from last year.
Token spend goes south (or does it)?
Perhaps more importantly, there’s some actual hard data to support the softer anecdata that token spending may be cooling:
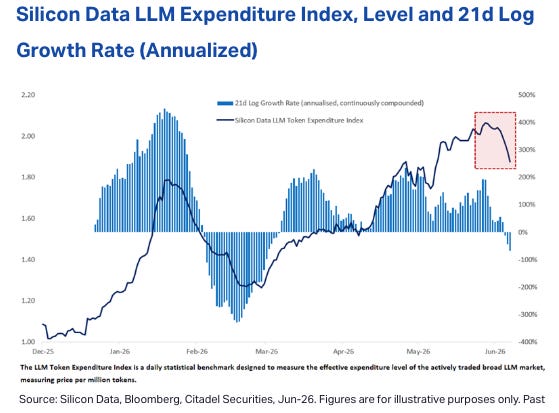
The Silicon Data token spend index, which purports to measure total token spend, shows some fairly substantial deceleration-to-decline in June.
Of course, Silicon Data is just one data source, and the index has declined before (only to shoot back up), so it’s way too early to declare “game over.”
Other data shows a slight wow dip, followed by a full recovery:
